
Power Automate Desktop
「OCR」アクションを使いこなす
Power Automate DesktopにはOCR用のアクションがいくつか用意されています。OCRとはOptical Character Recognition(Reader)の略で紙や画像ファイルに書かれている文字を、コンピュータで利用できるデジタルデータに変換する技術です。従来は中々精度が上がらず、実用まで至っていなかった技術ですが、AIの自然言語認識精度が劇的に向上したことにより実用化されるようになってきています。とはいえ、まだまだ日本語の認識に関しては精度が低いところもあるのですが、そこは今後の発展に期待して、ひとまずはひとつひとつのアクションの動きについて確認していきましょう。
(なお、2022/8/22執筆時点でのアクション数であり、今後、利用できるオプションが増える可能性があります。)
1. OCRの設定
「OCR」に関するアクションを実行するには、OCRの設定をすることが必須となります。すべてのアクションで共通の設定を行うので、最初にOCRの設定の仕方を解説していきます。
まずOCRエンジンの種類を選びます。「Windows OCR」「Tesseractエンジン」「OCRエンジン変数」の3つから選べますが、「OCRエンジン変数」については廃止予定で非推奨となっております。ここでは「OCRエンジン変数」を除いた設定の仕方を解説していきます。
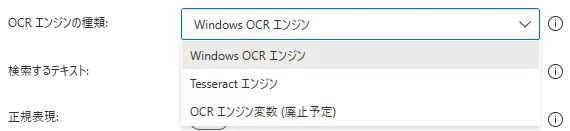
「Windows OCR」はWindows 10に標準搭載されているOCRです。日本のパソコンでは日本語の言語パックがデフォルト設定となっていますが、「設定>時刻と言語>言語>言語の追加」から他言語も追加可能です。「英語(米国)」を追加すると、下図のように日本語の下に英語(米国)が追加されます。
「Tesseractエンジン」を利用する場合は言語パックをインストールする必要があります。https://github.com/tesseract-ocr/tessdataから使いたい言語ファイルをダウンロードしてください。なお、日本語を使いたい場合はjpn.traineddataとjpn_vert.traineddataをダウンロードし、下図のように2ファイルを格納するためのフォルダを作成して、そこに入れてください。

「OCRエンジンの設定」では「Windows OCRエンジン」を選択するか、「Tesseractエンジン」を選択するかで入力内容が異なります。「Windows OCRエンジン」を選択した場合は、どの言語を使うか選択し、画像の幅と高さの乗数を設定します。デフォルトでは日本語しか使えません(他の言語を選択した場合は実行時にエラーが返ってきます。)が、先述のように他の言語をインストールした場合はその言語も使えるようになります。幅と高さの乗数を変更すると、乗数分、画像サイズを大きくしてOCRを実行してくれます。デフォルトでは元の画像サイズですが、読み取りがうまくいかない場合などに変更することができます。「Tesseractエンジン」を選択した場合は「英語」「ドイツ語」「スペイン語」「フランス語」「イタリア語」以外を使用する場合は「言語コード」と「言語データパス」を入力する必要があります。日本語を使いたい場合は「言語コード」に「jpn」を、「言語データパスに」に先述のjpn.traineddataとjpn_vert.traineddataのあるフォルダを指定してください。画像の幅と高さの乗数については「Windows OCRエンジン」の設定と同様です。

2. 検索モード
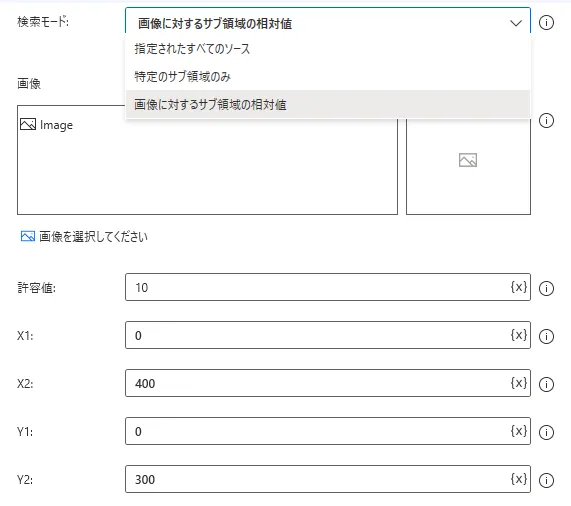
検索モードは各OCRアクションでテキストを検索する範囲を設定した際に、検索の詳細方法を設定する項目になります。「指定されたすべてのソース」「特定のサブ領域のみ」「画像に対するサブ領域の相対値」の選択肢から選びます。「指定されたすべてのソース」を選択した場合は、「テキストの検索先」や「OCRソース」で指定した範囲のすべてに対してOCRを行います。「特定のサブ領域のみ」を実行した場合は続く「X1(左側始点)」と「X2(右側終点)」でX座標を、「Y1(上側始点)」と「Y2右側終点)」でY座標を指定し、OCRを行いたい領域を絶対値で指定します。「画像に対するサブ領域の相対値」を選択した場合、最初に画像を選択します。その後、選択した画像とマッチする部分を中心にどれだけの領域を対象とするかを、「X1」と「X2」、「Y1」と「Y2」で対象範囲を相対的に決定します。「許容値」は指定した画像と元データのマッチ部分の違いをどれだけ許容するかの値のことであり、10をデフォルトとしつつ、値が小さくなるほど、厳格に違いを認識するようになります。
3. テキストが画面に表示されるまで待機(OCR)

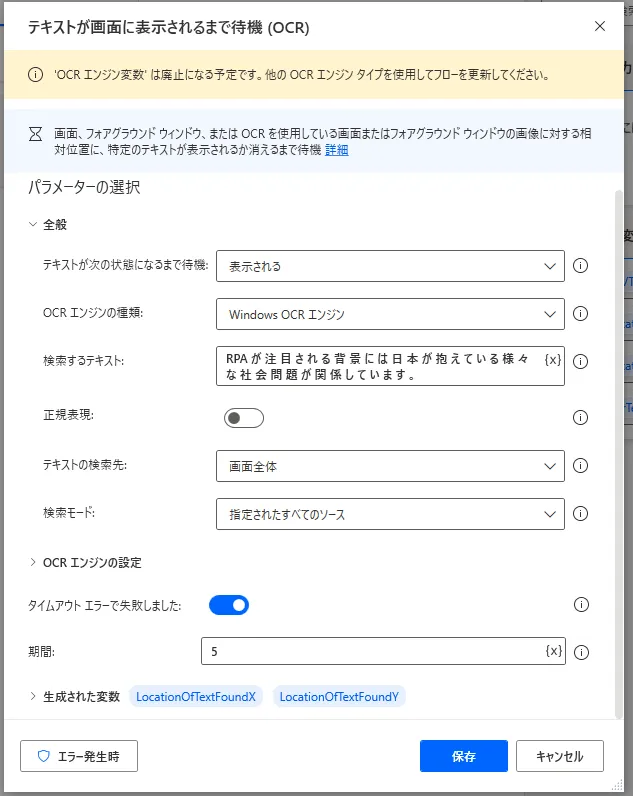
「テキストが画面に表示されるまで待機(OCR)」を利用すると、指定したテキストが画面に表示されるか、消えるまでRPAの実行を停めることができます。設定画面ではまずテキストが「表示される」まで待機するのか、「消える」まで待機するのか選択します。次に「OCRエンジンの種類」を「Windows OCRエンジン」か「Tesseractエンジン」から選択します。「OCRエンジン変数」もありますが、こちらは廃止予定で非推奨です。「検索するテキスト」には検索したいテキストを入力します。「正規表現」をONにすると、「検索するテキスト」に正規表現を使うことができます。「テキストの検索先」は画面全体を対象にするか、最前面のウィンドウである「フォアグラウンドウィンドウ」から選択します。「検索モード」と「OCRエンジンの設定」に関しては第1項「OCRの設定」と第2項「検索モード」に詳述していますので、そちらをご覧ください。「タイムアウトエラーで失敗しました」をONにすると続く「期間」からタイムアウトさせる秒数を入力できるようになります。
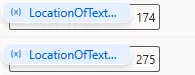
下図の画面を開いた状態で実行してみます。「検索対象のテキスト」は本文の1行目にあるので、待機せずRPAのアクションは実行され、実行後は合致したテキストの座標を取得できました。

読み取りがうまくいかない場合は「OCRを使ってテキストを抽出」アクションなどを使って、一度どういう風にテキストを取得できるか確認してみてください。例えば、今回、検索したいテキストを入力するとき、日本語と日本語の間には半角空白を空けています。というのも、テキストを読み取ったときに日本語のそれぞれの文字の間に半角空白があるとコンピュータが誤認識してしまっていたので、空白がないと適切に動かなったからです。

4. テキストが画面に表示される場合(OCR)
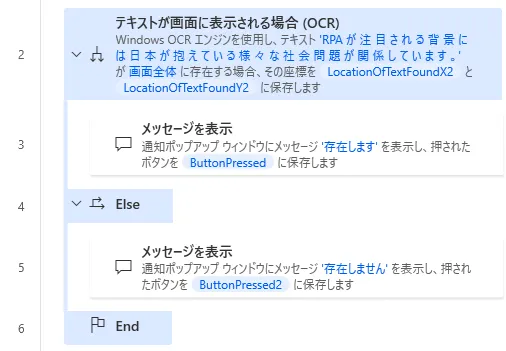
「テキストが画面に表示される場合(OCR)」を利用すると、「指定した画面」上に「指定したテキスト」がOCRで読み取れた場合に応じて条件分岐させることができます。上図のように「Else」アクションと併用して使用することができます。
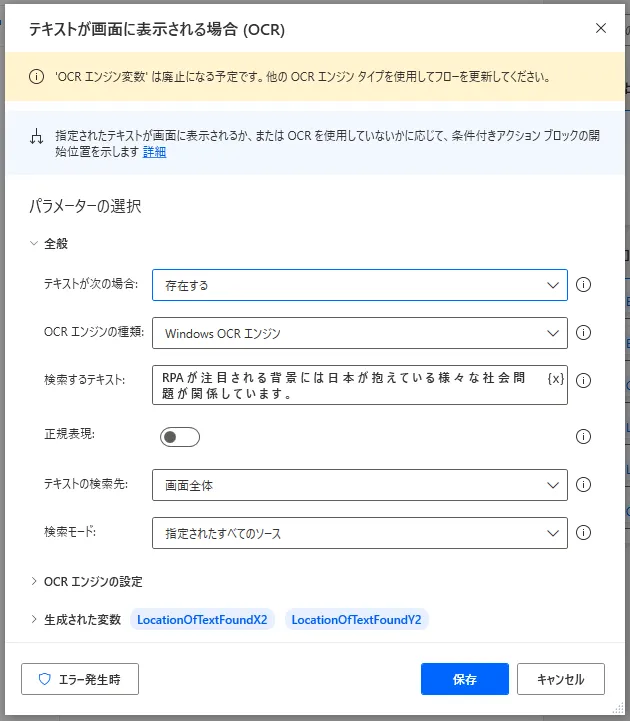
設定画面では、最初にテキストが「存在する」場合に真とするか、「存在しない」場合に真とするかを選択します。次にOCRエンジンを「Windows OCRエンジン」か「Tesseractエンジン」から選択します。「OCRエンジン変数」もありますが、こちらは廃止予定で非推奨となっています。次に条件とするテキストを入力します。正規表現をONにすると、「検索するテキスト」で正規表現を使えるようになります。「テキストの検索先」は画面全体から検索するか最前面のウィンドウから検索するか選択します。検索モード」と「OCRエンジンの設定」に関しては第1項「OCRの設定」と第2項「検索モード」に詳述していますので、そちらをご覧ください。
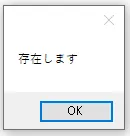
下図テキストを対象にRPAを実行した場合、テキスト本文の1行目に「検索するテキスト」が存在するため、真となり、メッセージが表示されます。なお、読み取りがうまくいかない場合は言語設定が「日本語」になっているかを確認し、「OCRを使ってテキストを抽出」アクションなどを利用し、実際に抽出されたテキストには各文字の間に半角空白が空いていないかなどを確認しましょう。

5. OCRを使ってテキストを抽出

「OCRを使ってテキストを抽出」アクションを利用すると、画面や画像上のテキストを読み取ることができます。設定画面ではまず使用する「OCRの種類」を選択します。「OCRソース」は「画面」「フォアグラウンドウィンドウ」「ディスク上の画像」から選択します。「画面」を選択すると、今、表示されている画面全体を、「フォアグラウンドウィンドウ」を選択した場合は、最前面にあるウィンドウを、「ディスク上の画像」とした場合は続く「画像ファイルパス」にある画像を対象にOCRを実行します。
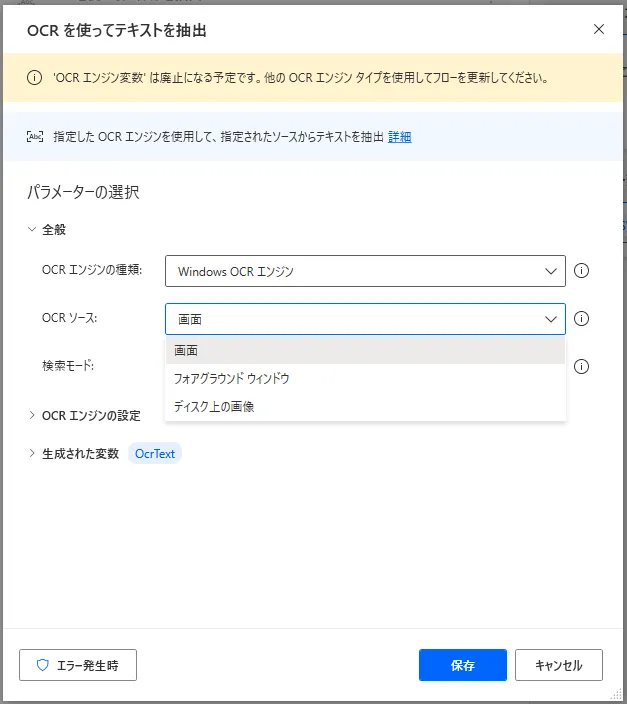
「検索モード」に関しては第2項「検索モード」を、「OCRエンジンの設定」に関しては第1項「OCRの設定」を参照ください。設定ができたら、下図のテキストをOCRで読みこませてみましょう。

読み込み結果は下図のようになりました。お世辞にも精度が高いとはまだ言えない結果ですね。

精度はよくて「7割」とかそのくらいでしょうか。他の言語はどうでしょう。下図のは米国ホワイトハウスのホームページにあった文章です。
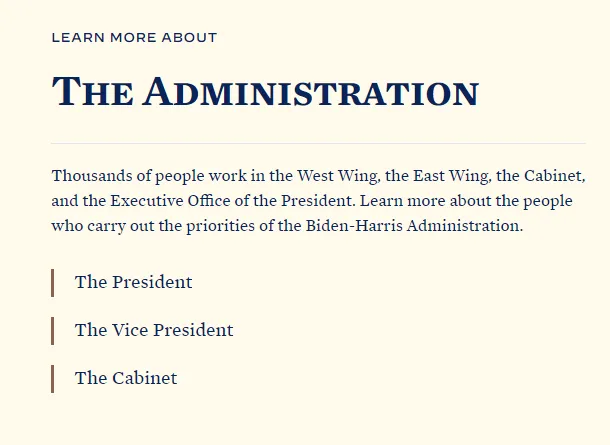
こちらを読み取ると、下図のようになります。ミスなく読み取れていますね。英語の精度が高いというのもありますが、一般的に日本語の認識はとても難しいと言われています。今後の発展に期待です。

以上、「OCR」アクションの解説でした。正直、2022年8月時点の段階では日本語で使うにはまだまだ精度が低いと言わざるを得ない技術でしょう。しかし、この分野の発展は目覚ましく、1年後には全く異なる精度になっていても不思議ではありません。すぐに使うということはないかもしれませんが、来るべき将来に備えて頭の片隅に置いておくくらいの価値はあるのではないかとは考えています。
→「Power Automate Desktop」の他の操作も見る執筆者プロフィール

伊藤 丈裕
(株)サムテックのシステムエンジニア。応用情報技術者資格保有。
27歳の時、営業から完全未経験で転職。開発とWebマーケティングを担当。得意言語はJavaとJavaScript。