
Power Automate Desktop
「PDF」アクションを使いこなす
Power Automate DesktopにはPDFを操作するためのアクションが複数用意されています。PDFはOSなどの環境に関わらず閲覧することができるため、広く利用されています。公文書などもPDFでアップロードされていることが多く、RPAで自動化を進めていくと、このPDFファイルを扱わなくてはいけない機会もあるでしょう。このページではそれらのアクションの動きをひとつひとつ確認していきます。
(なお、2022/8/24執筆時点でのアクション数であり、今後、利用できるオプションが増える可能性があります。)
1. PDFからテキストを抽出

「PDFからテキストを抽出」を利用するとPDFファイル内のテキストを取得できます。設定画面では、まずテキストを抽出したいPDFファイルをフルパスで入力します。次に抽出する範囲を「すべて」か「単一」か「範囲」から選択します。「単一」の場合は何ページ目を抽出するのか、「範囲」の場合は何ページ目から何ページ目までを抽出するのかを追加で入力します。PDFファイルにパスワードがかかっている場合は「詳細」でパスワードを入力してください。「構造化データに最適化」をONにすると、取得したデータを整形してくれます。
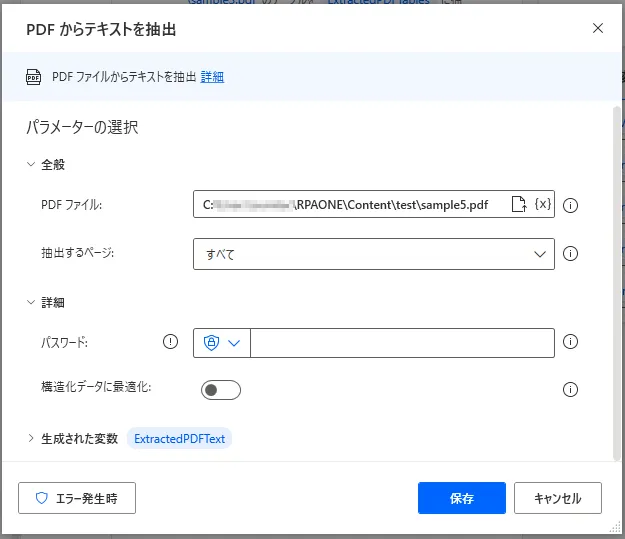
実行すると、下図のように取得したテキストが変数に格納されます。ただし、画像上の文字は読み取ることができません。
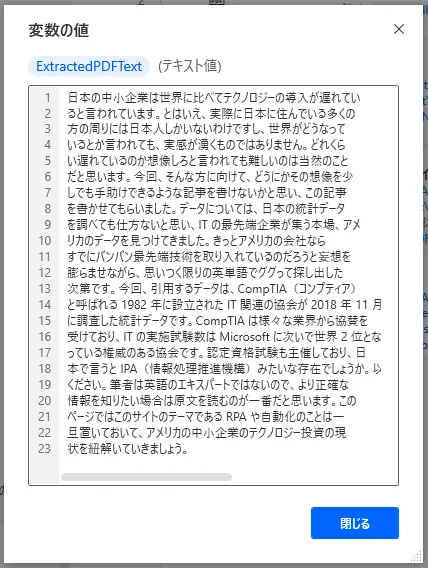
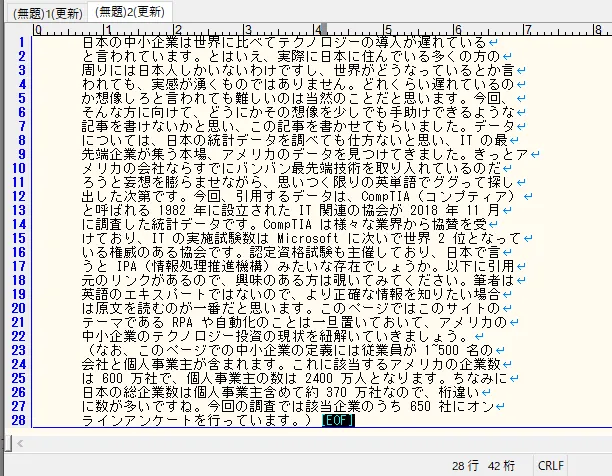
「構造化データに最適化」をONにした時の違いを見てみましょう。この違いはテキストエディタにコピー&ペーストしてみるとよくわかります。下図はサクラエディタにコピーした例ですが、1つ目が「構造化データに最適化」をOFFにした場合、2つ目がONにした場合となります。ONにすると、綺麗に整形してくれることが見てとれます。

2. PDFからテーブルを抽出する
「PDFからテーブルを抽出する」を利用するとPDFファイルのテーブルデータを取得することができます。設定画面ではまずテーブルを取得したPDFファイルをフルパスで入力します。続いて、抽出対象とするページを「すべて」か「単一」か「範囲」から選択します。「単一」と「範囲」を選択した場合は追加で対象のページも入力します。PDFファイルに鍵がかかっている場合は「詳細」の「パスワード」を入力してください。「ページの余白を越えるテーブルをマージする」をONにすると、テーブルデータがPDFファイルの中でページを跨いだ場合もひとつのデータとして扱ってくれます。OFFにすると分割されます。「最初の行に列名を含める」をONにすると、最初の行を列名として認識します。
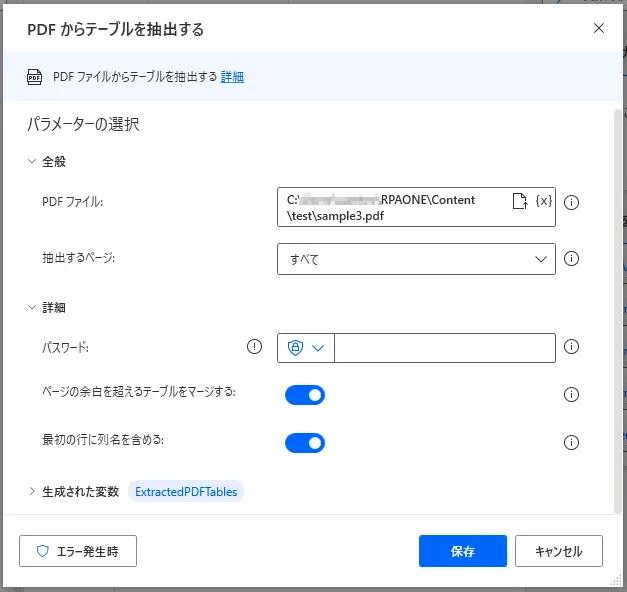
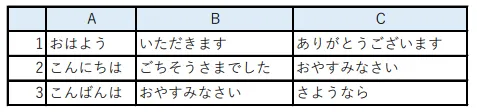
「実行すると、下図のようになります。行インデックスとして作られていた「1、2、3」もひとつの列として認識されて、列名はデフォルトの「Column1」が与えられています。とはいえ、おおむね綺麗に取得できているので、あとは取得後の操作でどうにか整えられそうな範囲です。
3. PDFから画像を抽出
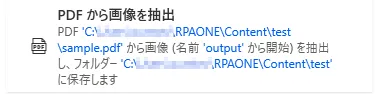
「PDFから画像を抽出」を利用すると、PDFファイル内にある画像を取得することができます。最初に画像を取得したいPDFファイルをフルパスで入力します。次に対象ページを「すべて」「単一」「範囲」から選択します。「単一」「範囲」を選択した場合は追加で対象のページも入力します。取得した画像は「〇〇_0」「〇〇_1」「〇〇_2」…と名付けられるので、「画像名」にこの〇〇に当てはめたい名前を入力してください。「画像の保存先」には取得した画像を保存したいフォルダを入力します。PDFファイルに鍵がかかっている場合は「パスワード」を「詳細」から入力してください。
実行すると、指定したフォルダに取得した画像が保存されました。

4. 新しいPDFファイルへのPDFファイルページの抽出
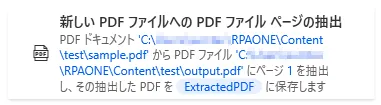
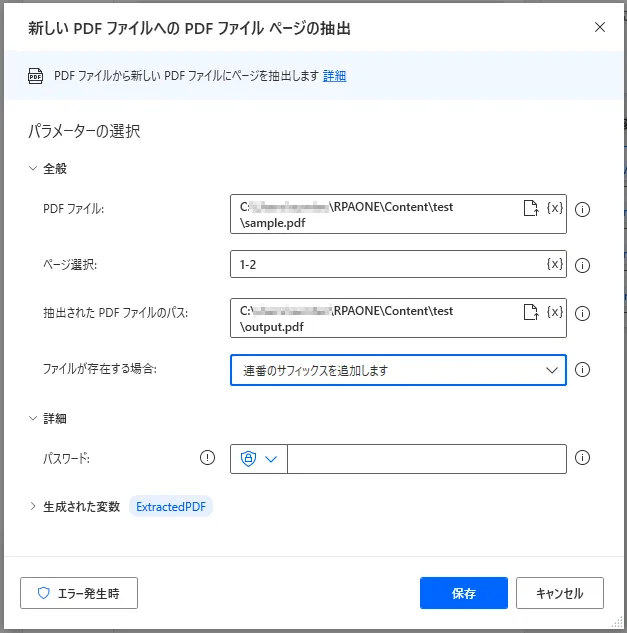
「新しいPDFファイルへのPDFファイルページの抽出」を利用すると、PDFファイルの指定したページ分を新しいPDFファイルにコピーして作成することができます。設定画面ではまず対象となるPDFファイルを入力します。続いてファイルのどのページを対象とするか入力しましょう。下図のように「-(ハイフン)」を使えば、何ページから何ページまでと指定できます。「,(カンマ)」を使うと、ページを個別で複数選択することができます。例えば「1,4,7」とした場合は1ページと4ページと7ページといった感じになります。組み合わせることも可能で、「1-3, 5, 7-9」とした場合は4ページと6ページを除いた1~9ページとなります。「抽出されたPDFファイルのパス」にはどのファイルに抽出したページ内容をコピーするか入力します。「ファイルが存在する場合」は既に指定した先にファイルが存在する場合の挙動を設定でき、「上書き」「上書きしない」「連番のサフィックスを追加します」から選ぶことができます。「上書き」にすると既存のファイル内容を上書きし、「上書きしない」にした場合は何もせず処理を終了します。「連番のサフィックスを追加します」とすると、連番を追加することで新しいファイルを作成し、そこに抽出したページ内容をコピーします。
実行すると、指定したフォルダにPDFファイルが作成され、その中身は元となったファイルで指定した2ページ分だけ作成されました。
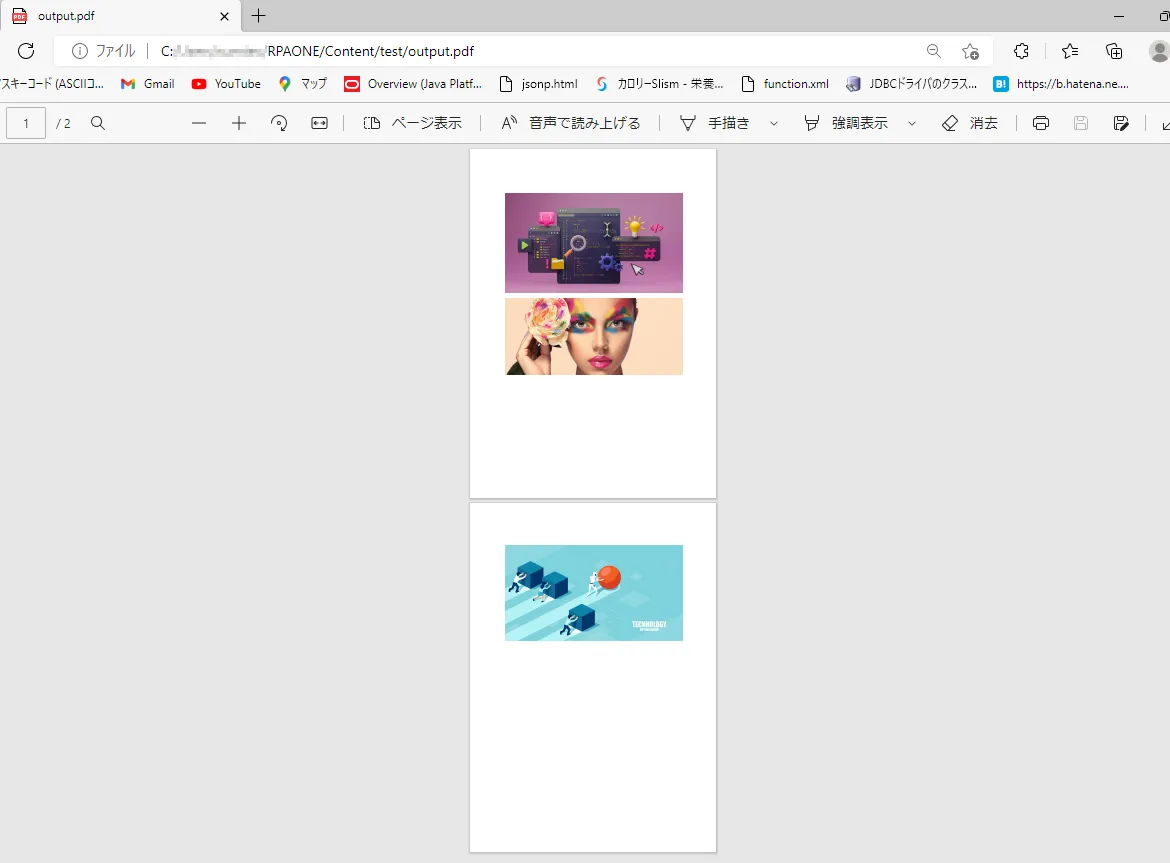
5. PDFファイルの統合
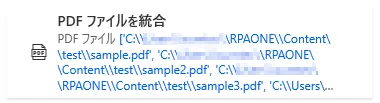
「PDFファイルを統合」を利用すると複数のPDFファイルをひとつにまとめることができます。設定画面ではまず対象のPDFファイルを選択します。この際、対象にしたいファイルは下図のようにリストにして一度に選択します。次に統合後のファイル保存先を「統合されたPDFのパス」に入力しましょう。「ファイルが存在する場合」からは既に指定した保存先にファイルがある場合の挙動を設定できます。「上書き」にすると、既存のファイルを上書き保存します。「上書きしない」にすると、何もせず終了します。「連番サフィックスを追加します」にすると、ファイル名に連番を追加して新しいファイルに保存します。PDFファイルに鍵がかかっている場合は「詳細」にある「パスワード」に入力します。
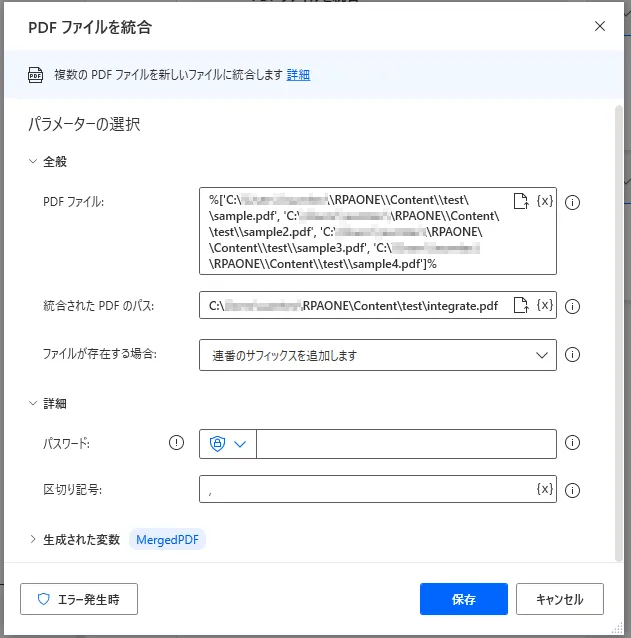
複数ファイルを指定した場合、ファイルにもそれぞれ鍵がかかっている場合があります。その時は「区切り番号」に入力した記号で区切りつつ、リストの順番でパスワードを入力してください。例えば、「,,,,111111,222222」だと1~4つ目のファイルにはパスワードが設定されておらず、5つ目のファイルには「1111111」というパスワードが、6つ目のファイルには「2222222」というパスワードが設定されている場合に入力します。

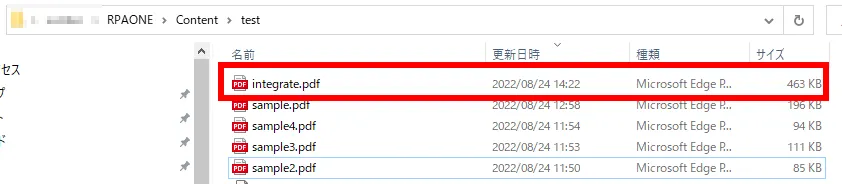
実行してみると、下図のように指定したフォルダに統合されたPDFファイルが新しく作成されます。
以上、「PDF」アクションの解説でした。このアクションをうまく活用することで、情報収取作業の自動化などRPAでできることの幅が広がってくるでしょう。
→「Power Automate Desktop」の他の操作も見る執筆者プロフィール

伊藤 丈裕
(株)サムテックのシステムエンジニア。応用情報技術者資格保有。
27歳の時、営業から完全未経験で転職。開発とWebマーケティングを担当。得意言語はJavaとJavaScript。