
RPAとPython、
それぞれの自動化の違い
パソコン操作の自動化と聞いた時に、「Python」を使えるのではないかと思われる方もいるかもしれません。Pythonはライブラリが充実しており、自動化するためのツールも豊富にあります。一方で、RPAもパソコン上の事務作業を自動化することができます。では、RPAとPythonの違いは何でしょうか。それはPythonがプログラミング言語であり、RPAはパソコン上の作業を自動化するためのツールであるという点です。Pythonを実行する場合は、「~.py」と書かれたファイルを用意し、その中にPythonで行わせたい命令をプログラミングで書いてあげる必要があります。一方で、RPAの場合はベンダーと呼ばれるソフトウェアを提供してくれる会社がRPAの作成から管理、実行までできるツールを提供してくれるので、その中で完結することができます。
とはいえ、ここで言葉だけで説明しても違いが良くわからないのではないでしょうか。ここでは簡単な事例を通して、RPAとPythonの違いについて具体的に見ていきたいと思います。RPAツールは「Power Automate Desktop」というMicrosoftが提供している無料のツールを使っていきます。PythonはVSコードという開発ツールを使って作っていきます。
今回の題材はGoogleを起動し、そこの検索ボックスに「RPAとPythonの違い」と入力し、検索。検索結果の一番上のリンクをクリックし、キャプチャしてOneDriveに保存するということをPythonとRPAでそれぞれ実現していきたいと思います。
→RPAについての簡単な概要はこちら1. Pythonで実装
まずはPythonでの実装方法を見ていきます。色々、細かい所は後で説明していきますが、実装のコードは以下のようになります。
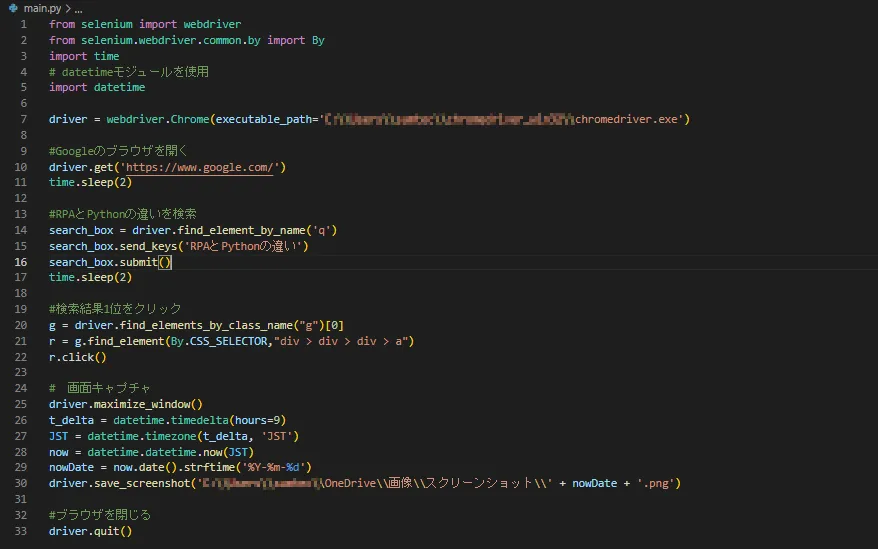
思っていたよりコードが少なかったでしょうか。そうなんです。実はライブラリと呼ばれる他の方がすでに作ってくれている機能を利用すれば、案外簡単にできてしまうんですね。それでは実際にひとつひとつ見ていきましょう。今回はブラウザの動きを自動化していくためのツールとしてseleniumというライブラリを使います。場合によってはseleniumの下に黄色い波線が出てうまく動作しないことがあるかもしれません。その時はVSコード下部にあるターミナルというところから「pip install selenium」と入力し、seleniumをダウンロードするようにしてください。詳しい方法は下記リンク先を参照ください。

次にブラウザを操作するために使用する予定のブラウザのドライバーをパソコンにダウンロードする必要があります。詳しいダウンロード方法は下記リンク先をご覧ください。ダウンロードが終わったら、ダウンロードしたファイルに以下のようにパスを通します。パスは「~.exe」と書かれているファイルにパスを通すようにしてください。筆者のパソコンにはChromeとEdgeしか入っていないので、今回はこの2つの書き方を紹介しますが、FireFoxなどの他のブラウザでも同じように動くはずです。

ここまでできたらブラウザを操作できるようになっているので、以下のように入力してGoogleの検索画面を開きます。ここで「time.sleep(2)」としているのはGoogleのブラウザを起動させている間に処理が進まないように処理を一時停止させるためです。「2」は2秒一時停止させることを意味していますが、ここは何秒でも問題はありません。2秒あれば多少ネットの環境が悪くても検索画面が開けるだろうということで2秒にしました。

さて、ここまでできればGoogleの検索画面が開けているはずです。次は実際に検索を行うためのコードを書いていきます。15行目は「q」というname属性を持つ要素を取得するコードを書いています。こちらはHTMLの知識になりますが、HTMLは何種類ものタグの組合せでできており、そのタグには属性を持たせることができます。属性を持たせることでその属性に合致した値を取得したり、CSSと言われるHTMLを装飾させる技術をより使いやすくしたりします。属性にはname属性、class属性、id属性などデフォルトで用意されているものもありますが、各開発者が必要に応じてカスタマイズすることもできます。
話がそれてしましましたが、16行目は実際に取得した要素(ここではGoogleの検索ボックス)に検索ワードを入力しています。そして17行目で実際に検索を実行しています。ここでも検索結果が反映されるまで2秒ほど処理を停止させています。

ここまで正常に動いていれば、「RPAとPythonの違い」というキーワードで検索した結果画面が表示されているはずです。21行目は検索結果画面から「g」というクラス属性を持つ要素を取得します。最後の「0」は複数取得した要素のうちの一番最初の要素だけを取得するようにしています。22行目は21行目で取得した子要素からアンカータグ(aタグ)と呼ばれるページを遷移させるためのタグを探し出しています。アンカータグを探した後に23行目でそのアンカータグをクリックさせ、実際にページを遷移させます。

ちなみに21行目の最後に「0」がついているのは、「g」というクラス属性を持っている要素が実際の画面で言うと下図のように各検索結果のブロックを表しており、Googleだと検索結果が1ページに10個出てくるので、複数あるためです。最後のブロックをクリックしたい場合は「10」に書き換えれば良いわけですね。
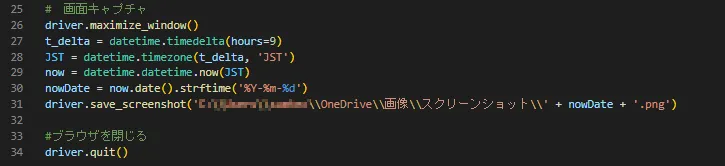
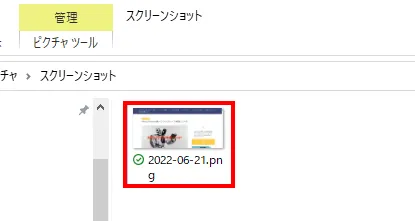
さて、こちらで最後の処理になりますが、前のコードで目的の画面を開くことができました。26行目でウィンドウの大きさを最大化し、27~30行目でファイル名を付けるための現在日付を取得、整形しています。31行目で画面をスクリーンショットして、()内の形式で保存します。最後、ブラウザを閉じて、操作完了です。
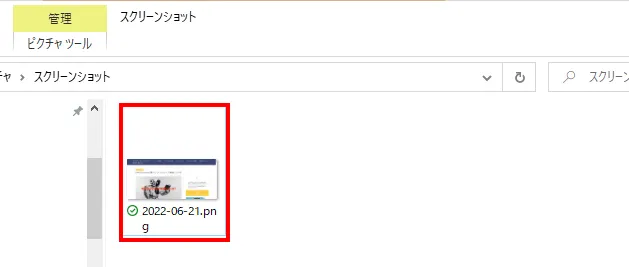
実行結果は以下のような形に指定したフォルダの中にファイルができていれば成功です。ちょっと難しかったでしょうか。次はRPAの実装方法について解説していきます。Pythonでの実装に比べてプログラミングがないので、少しは簡単に思えるかもしれませんよ。
2. RPAで実装
続いてRPAでの実装を見ていきましょう。まずは結果から。今回のシナリオは下図の通りになります。思っていたより簡単でしたか。Pythonでの実装に比べてコードがないので、見やすいですね。
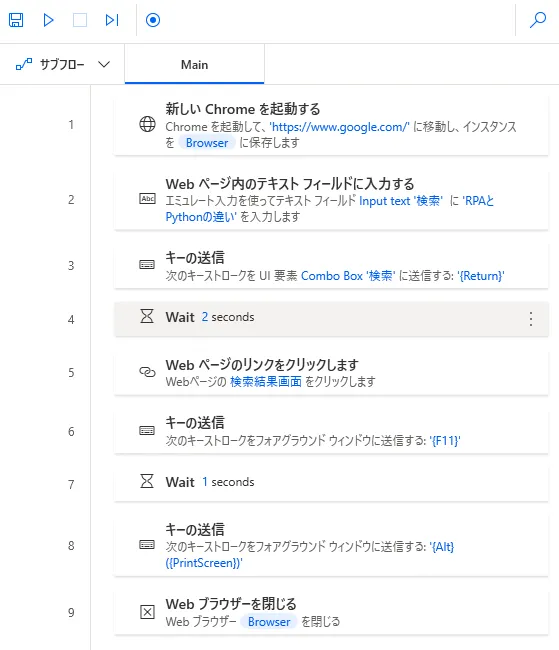
手順としては手順1で新しくブラウザを起動します。2で検索ボックスに検索ワードを入力します。3でEnterキーを押して検索を実行します。その後、検索結果が反映されるまで少し時間を置いてから、あらかじめ下図のようにして登録しておいたWebページのリンクをクリックします。手順5できちんとクリックできたら、目的の画面があらわれるので、手順6で画面を最大化する操作を行い、最後スクリーンショットを撮って、ブラウザを閉じたら操作完了です。
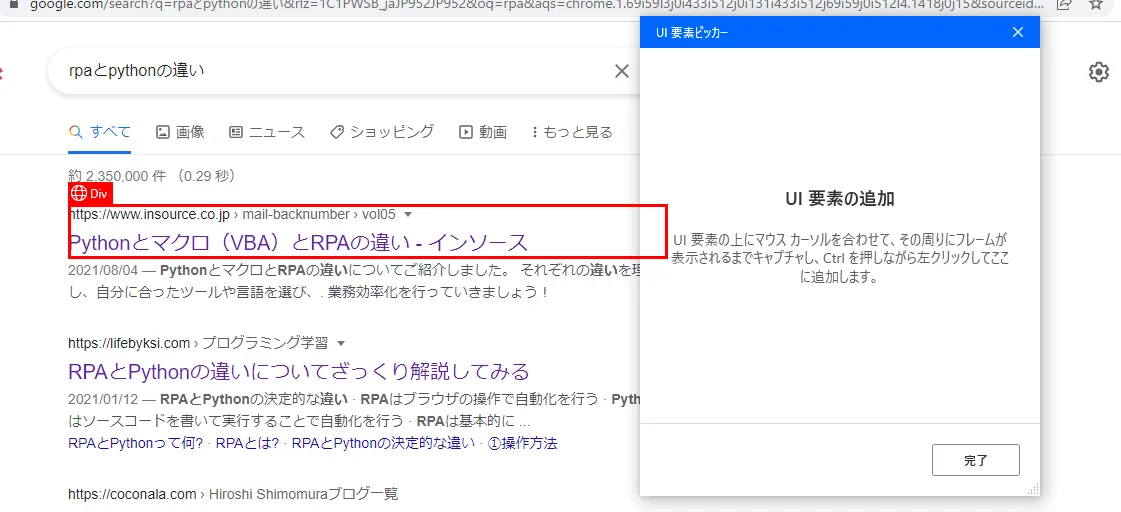
勘の鋭い人は気づいたかもしれませんが、手順5のWebページのクリック、こちらは必ずしも最初の検索結果を取ってくるとは限りません。上図のようにしてUI要素を追加した場合、その検索結果に対しては有効ですが、検索条件を変えた場合や検索結果の順番が変わった場合、同じように動く保証はありません。(もちろん、きちんと動くこともあります。)
Power Automate Desktopでは一番右側のサイドバーにあるUI要素のアイコンから追加したUI要素の中身を確認することができます。
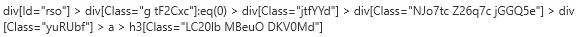
先ほどのUI要素を追加したすぐの状態だと上図のようになっていますが、下図のように変更したところ、より適用できる範囲が広くなりました。(本当は「tF2Cxc」というクラスも取り除きたかったのですが、うまくできませんでした。好きなようにカスタマイズできるわけではないみたいです。)
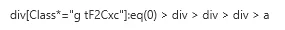
以上のように若干の融通の利かなさもありますが、うまく動作をすれば以下のように同じような結果になります。
RPAは反復、定型作業が得意で、非定型作業は苦手と言われていますが、その理由を垣間見ることができますね。とはいえ、プログラミングを知らない人からしてみれば、目で見て直観的に作ることのできるRPAツールはとっても便利です。ぜひRPAツールを上手に活用して、時間を有効活用していきましょう。
執筆者プロフィール

伊藤 丈裕
(株)サムテックのシステムエンジニア。応用情報技術者資格保有。
27歳の時、営業から完全未経験で転職。開発とWebマーケティングを担当。得意言語はJavaとJavaScript。